- Topic1/3
806 Popularity
22k Popularity
5k Popularity
4k Popularity
170k Popularity
- Pin
- Hey fam—did you join yesterday’s [Show Your Alpha Points] event? Still not sure how to post your screenshot? No worries, here’s a super easy guide to help you win your share of the $200 mystery box prize!
📸 posting guide:
1️⃣ Open app and tap your [Avatar] on the homepage
2️⃣ Go to [Alpha Points] in the sidebar
3️⃣ You’ll see your latest points and airdrop status on this page!
👇 Step-by-step images attached—save it for later so you can post anytime!
🎁 Post your screenshot now with #ShowMyAlphaPoints# for a chance to win a share of $200 in prizes!
⚡ Airdrop reminder: Gate Alpha ES airdrop is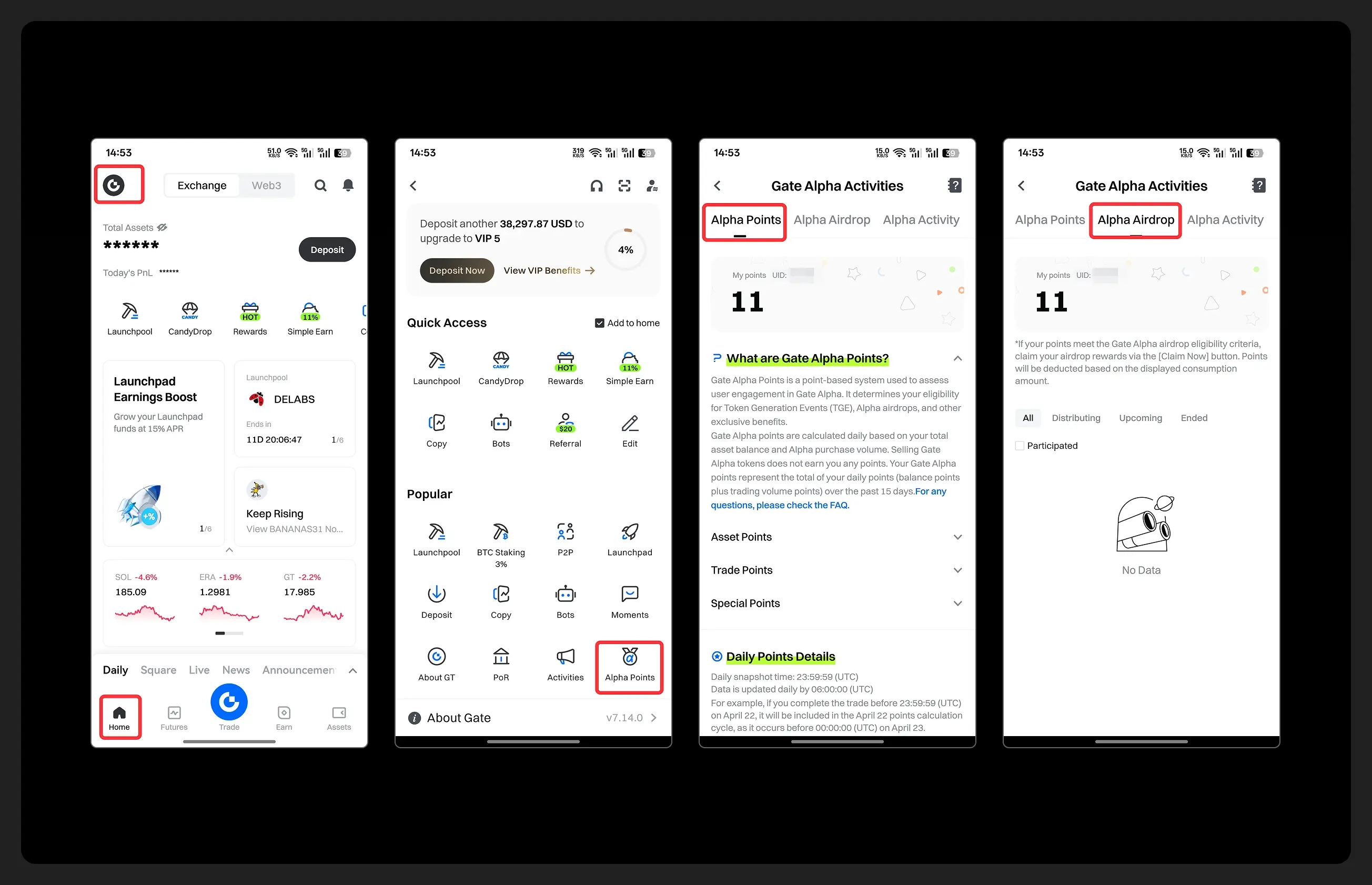
- Gate Futures Trading Incentive Program is Live! Zero Barries to Share 50,000 ERA
Start trading and earn rewards — the more you trade, the more you earn!
New users enjoy a 20% bonus!
Join now:https://www.gate.com/campaigns/1692?pid=X&ch=NGhnNGTf
Event details: https://www.gate.com/announcements/article/46429
- Hey Square fam! How many Alpha points have you racked up lately?
Did you get your airdrop? We’ve also got extra perks for you on Gate Square!
🎁 Show off your Alpha points gains, and you’ll get a shot at a $200U Mystery Box reward!
🥇 1 user with the highest points screenshot → $100U Mystery Box
✨ Top 5 sharers with quality posts → $20U Mystery Box each
📍【How to Join】
1️⃣ Make a post with the hashtag #ShowMyAlphaPoints#
2️⃣ Share a screenshot of your Alpha points, plus a one-liner: “I earned ____ with Gate Alpha. So worth it!”
👉 Bonus: Share your tips for earning points, redemption experienc
- 🎉 The #CandyDrop Futures Challenge is live — join now to share a 6 BTC prize pool!
📢 Post your futures trading experience on Gate Square with the event hashtag — $25 × 20 rewards are waiting!
🎁 $500 in futures trial vouchers up for grabs — 20 standout posts will win!
📅 Event Period: August 1, 2025, 15:00 – August 15, 2025, 19:00 (UTC+8)
👉 Event Link: https://www.gate.com/candy-drop/detail/BTC-98
Dare to trade. Dare to win.
The Integration of AI and Blockchain: From Technological Evolution to Industry Chain Layout
The Integration of AI and Blockchain: From Technology to Application
The rapid development of the artificial intelligence industry in recent times is seen by some as the beginning of the Fourth Industrial Revolution. The emergence of large language models has significantly improved efficiency across various industries, estimated to have increased overall work efficiency in the United States by about 20%. At the same time, the generalization ability brought by large models is considered a brand new software design paradigm. Compared to the precise code design of the past, modern software development is more about embedding the strong generalization frameworks of large models into software, giving it greater expressiveness and a wider range of input and output capabilities. Deep learning technology has indeed brought a new wave of prosperity to the AI industry, and this trend has gradually spread to the cryptocurrency industry.
This report will detail the development history of the AI industry, the classification of technologies, and the impact of the invention of deep learning technology on the industry. It will then analyze the current status and trends of the upstream and downstream of the industrial chain in deep learning, including GPUs, cloud computing, data sources, and edge devices. After that, it will fundamentally explore the relationship between the Crypto and AI industries, and outline the structure of the AI industrial chain related to Crypto.
Development History of the AI Industry
The AI industry began in the 1950s. To realize the vision of artificial intelligence, academia and industry have developed various schools of thought for achieving artificial intelligence across different eras and disciplinary backgrounds.
Modern artificial intelligence technology primarily uses the term "machine learning", the core idea of which is to enable machines to iteratively improve system performance in tasks based on data. The main steps involve inputting data into algorithms, training models with this data, testing and deploying models, and using models to complete automated prediction tasks.
Currently, there are three main schools of thought in machine learning: connectionism, symbolism, and behaviorism, which respectively mimic the human nervous system, thinking, and behavior.
Currently, connectionism represented by neural networks is prevailing ( also known as deep learning ). The main reason is that this architecture has an input layer, an output layer, but multiple hidden layers. Once the number of layers and the number of neurons ( parameters ) become sufficient, there will be enough opportunities to fit complex general tasks. Through data input, the parameters of the neurons can be continuously adjusted, and after experiencing multiple data, the neuron will reach an optimal state ( parameters ), which is also known as the "depth" - enough layers and neurons.
Based on deep learning technology using neural networks, there have been multiple iterations and evolutions, from the earliest neural networks to feedforward neural networks, RNNs, CNNs, GANs, and finally evolving into modern large models like those using Transformer technology such as GPT. The Transformer technology is just one direction of evolution for neural networks, adding a converter ( Transformer ), which is used to encode data from all modalities ( such as audio, video, images, etc. ) into corresponding numerical representations. This data is then input into the neural network, allowing the neural network to fit any type of data, achieving multimodality.
The development of AI has gone through three technological waves. The first wave occurred in the 1960s, a decade after AI technology was proposed. This wave was driven by the development of symbolic technology, which addressed issues of general natural language processing and human-computer dialogue. During the same period, expert systems were born, exemplified by the DENRAL expert system completed by Stanford University. This system possesses very strong chemical knowledge and infers answers similar to those of a chemical expert through questions. This chemical expert system can be seen as a combination of a chemical knowledge base and an inference system.
The second wave of AI technology occurred in 1997, when IBM's Deep Blue defeated chess champion Garry Kasparov with a score of 3.5:2.5. This victory is regarded as a milestone in artificial intelligence.
The third wave of AI technology occurred in 2006. The three giants of deep learning, Yann LeCun, Geoffrey Hinton, and Yoshua Bengio, proposed the concept of deep learning, an algorithm based on artificial neural networks for representation learning of data. Since then, deep learning algorithms have gradually evolved, from RNNs and GANs to Transformers and Stable Diffusion; these algorithms have collectively shaped this third wave of technology, marking the peak of connectionism.
Deep Learning Industry Chain
The current large model languages are all based on deep learning methods using neural networks. Led by GPT, large models have created a wave of artificial intelligence enthusiasm, with numerous players flooding into this field. We also find that the market's demand for data and computing power has surged significantly. Therefore, in this part of the report, we mainly explore the industrial chain of deep learning algorithms. In the AI industry dominated by deep learning algorithms, how are the upstream and downstream composed, and what are the current situations, supply and demand relationships, and future developments of the upstream and downstream?
First, we need to clarify that when training LLMs led by GPT based on Transformer technology, it is divided into three steps.
Before training, since it is based on Transformer, the converter needs to convert the text input into numerical values, a process known as "Tokenization". Afterwards, these numerical values are referred to as Tokens. Under general empirical rules, an English word or character can be roughly considered as one Token, while each Chinese character can be roughly viewed as two Tokens. This is also the basic unit used for GPT pricing.
The first step is pre-training. By providing enough data pairs to the input layer, we search for the optimal parameters of each neuron under the model. At this stage, a large amount of data is required, and this process is also the most computationally intensive, as it involves repeatedly iterating over the neurons to try various parameters.
The second step, fine-tuning. Fine-tuning involves training with a smaller batch of high-quality data, and such changes will lead to higher quality outputs from the model because pre-training requires a large amount of data, but much of that data may contain errors or be of low quality.
Step three, reinforcement learning. First, a brand new model will be established, which we call the "reward model". The purpose of this model is very simple: to rank the output results. Then, this model will be used to determine whether the output of our large model is of high quality, allowing us to automatically iterate the parameters of the large model using a reward model.
In short, during the training process of large models, pre-training has very high requirements for the amount of data, and the GPU computing power required is also the highest. Fine-tuning requires higher quality data to improve parameters, while reinforcement learning can iteratively adjust parameters through a reward model to produce higher quality results.
During the training process, the more parameters there are, the higher the ceiling of its generalization ability. Therefore, the performance of large models is mainly determined by three aspects: the number of parameters, the amount and quality of data, and computing power. These three factors jointly influence the quality of the results and the generalization ability of large models.
The Relationship Between Crypto and AI
Blockchain benefits from the development of ZK technology, evolving into the ideas of decentralization + trustlessness. Let's go back to the beginning of blockchain creation, which is the Bitcoin chain. In Nakamoto's paper, it is first referred to as a trustless, value transfer system. Afterwards, Vitalik and others published papers introducing a decentralized, trustless, value exchange smart contract platform.
Returning to the essence, we believe that the entire Blockchain network is a value network, where each transaction is a value conversion based on the underlying tokens. The value here is embodied in the form of Tokens, and Tokenomics is the set of rules that specifically reflects the value of the Tokens.
Tokens and blockchain technology, as a means of redefining and discovering value, are crucial for any industry, including the AI industry. In the AI industry, issuing tokens allows for the reshaping of value across various aspects of the AI industry chain, which will encourage more people to deeply engage in various segments of the AI field, as the benefits brought about will become more significant. The current value will not only be determined by cash flow, but the synergistic effect of tokens will enhance the value of the infrastructure, which will naturally lead to the formation of a fat protocol and thin application paradigm.
Secondly, all projects in the AI industry chain will benefit from capital appreciation, and this token can feed back into the ecosystem and promote the birth of a certain philosophical thought.
The impact of token economics on the industry clearly has its positive aspects. The immutable and trustless nature of blockchain technology also has practical significance for the AI industry, enabling applications that require trust, such as allowing our user data to be on a certain model, while ensuring that the model does not know the specific data, ensuring that the model does not leak data, and ensuring that the real data inferred from the model is returned. When GPUs are insufficient, distribution can be achieved through the blockchain network. When GPUs iterate, idle GPUs can contribute computing power to the network, rediscovering residual value, which is something that can only be achieved by a global value network.
In short, token economics can facilitate the reshaping and discovery of value, and decentralized ledgers can solve trust issues, allowing value to flow globally again.
Overview of AI-related Projects in the Crypto Industry
( GPU Supply Side
Currently, the most commonly used project is Render, which was launched in 2020 and is mainly used for video rendering tasks that are not related to large models. The scenarios that Render targets are different from AI, so it does not strictly belong to the AI sector. Moreover, there is indeed a certain real demand for its video rendering services, so the GPU cloud computing market can not only cater to the training and inference of AI models but can also be applied to traditional rendering tasks, which reduces the risk of the GPU cloud market relying on a single market.
In the Crypto industry chain regarding AI, the supply of computing power is undoubtedly the most important point. According to industry forecasts, the demand for GPU computing power is about $75 billion in 2024, and approximately $773 billion in market demand by 2032, with an annual compound growth rate of 33.86%.
The iteration rate of GPUs follows Moore's Law ), with performance doubling every 18-24 months and prices halving ###. Therefore, the demand for shared GPU computing power will become immense due to the explosion in the GPU market. Under the influence of Moore's Law in the future, a large number of non-latest generations of GPUs will be formed. At this time, these idle GPUs will continue to exert their value as long-tail computing power in the shared network. Hence, we are indeed optimistic about the long-term potential and practical utility of this sector, not only for small and medium models but also for traditional rendering businesses, which will create strong demand.
( data
The currently launched projects include EpiK Protocol, Synesis One, and Masa, with the difference being that EpiK Protocol and Synesis One focus on the collection of public data sources, while Masa is based on ZK technology, enabling the collection of private data, making it more user-friendly.
Compared to other traditional data companies in Web2, Web3 data providers have advantages on the data collection side, as individuals can contribute their non-private data. This broadens the project's reach, not just to businesses (ToB), but also allows for pricing of data from any user, giving value to all past data. Additionally, due to the existence of token economics, the network value and price are interdependent; zero-cost tokens will also increase as the network value rises. These tokens will reduce developers' costs and be used to reward users, thereby enhancing users' motivation to contribute data.
![Newcomer Science Popularization丨AI x Crypto: From Zero to Peak])https://img-cdn.gateio.im/webp-social/moments-250a286e79261e91a0e7ac4941ff5c76.webp(
) ZKML
If data wants to achieve privacy computing and training, the main ZK solutions currently adopted in the industry use homomorphic encryption technology to infer data off-chain and then upload the results along with the ZK proof, which can ensure the privacy of the data and inference.